HAMi AI Platform Edition Air-Gapped Deployment Guide
This document is intended for SRE / platform engineers. It describes how to deploy HAMi AI Platform in a Kubernetes cluster using the All-in-One air-gapped package, and complete license activation, GPU node enablement, and sample workload validation.
This delivery package uses Zarf to perform image import, Helm chart installation, and subsequent upgrades in environments without external network access or with restricted networks, reducing the manual effort of syncing images and maintaining installation order.
Zarf is an application packaging and deployment tool for Kubernetes air-gap / semi-air-gap environments; it can bundle images, Helm charts, scripts, and deployment actions into a portable package.
The installation itself does not depend on a licence; you can complete the deployment first, then apply for and import the licence in subsequent steps.
In short: install the software first, then obtain the licence; if not activated, vGPU partitioning and scheduling functionality will be unavailable, and function verification will also fail.
Air-Gapped Package Contents
The outer delivery package naming convention is:
hami-ai-platform-v<VERSION>-airgap-<ARCH>.tar.gz
hami-ai-platform-v<VERSION>-airgap-<ARCH>.tar.gz.sha256
The current hami-ai-platform-v0.0.2-airgap-amd64.tar.gz contains the following key files:
| File | Purpose |
|---|---|
zarf-linux-amd64 | Linux amd64 Zarf CLI |
zarf-init-amd64-v0.76.0.tar.zst | Zarf init air-gapped package |
hami-ai-platform-v0.0.2-airgap-amd64.tar.zst | HAMi AI Platform main deployment package |
zarf-package-hami-example-gpu-burn-amd64-v0.0.1.tar.zst | GPU burn sample validation package |
zarf-package-hami-example-vllm-qwen-amd64-v0.0.2.tar.zst | vLLM + Qwen sample validation package |
kantaloupe/ | kantaloupe values examples and full values documentation |
hami/README.md | hami-enterprise full values documentation |
collect-hami-license-info.sh | License application information collection script |
collect-cluster-info.sh | Cluster diagnostic information collection script |
Use the following command to inspect the contents of the outer package and verify the deliverables are complete:
tar -tvf hami-ai-platform-v0.0.2-airgap-amd64.tar.gz
Prerequisites Checklist
| Type | Requirement | Verification Command |
|---|---|---|
| Kubernetes | ≥ 1.24 | kubectl version --short |
| Container Runtime | containerd or Docker | kubectl get nodes -o wide |
| Helm | ≥ 3.14 | helm version --short |
| GPU Driver | NVIDIA driver ≥ 470 (recommended ≥ 550) | nvidia-smi |
| Prometheus CRD | Prometheus monitoring CRD must be installed to be compatible with different monitoring metric collection systems: Prometheus, VictoriaMetrics, etc. | kubectl api-resources | grep monitoring.coreos.com/v1 |
| GPU Operator | Installed and devicePlugin.enabled = false, recommended version: v25.3.2) | helm list -A | grep gpu-operator |
| Storage Space | Recommended greater than 30 GB | df -h |
Key Constraint: HAMi includes its own device-plugin, which conflicts with the built-in device-plugin of the NVIDIA GPU Operator. If GPU Operator is already installed, be sure to disable its built-in plugin with --set devicePlugin.enabled=false.
Extract, Verify, and Install Zarf
# Download delivery package and checksum file
curl -L -O <URL>
curl -L -O <SHA256_URL>
# Verify integrity
shasum -a 256 -c hami-ai-platform-v0.0.2-airgap-amd64.tar.gz.sha256
# Extract outer tar.gz
tar -xzf hami-ai-platform-v0.0.2-airgap-amd64.tar.gz
# Enter extracted directory
cd hami-ai-platform-v0.0.2-airgap-amd64
The delivery package already includes the Linux amd64 version of the Zarf CLI. After entering the extracted directory, install the bundled Zarf first:
chmod +x ./zarf-linux-amd64
sudo install -m 0755 ./zarf-linux-amd64 /usr/local/bin/zarf
zarf version
Zarf includes the Helm tool. For subsequent troubleshooting of Helm release, values, and chart status, use zarf tools helm to avoid relying on a separately installed Helm in the target environment:
zarf tools helm version
zarf tools helm list -A
Initialize Zarf
Before deploying a Zarf package to the target cluster for the first time, run zarf init.
Use the Zarf built-in registry:
zarf init zarf-init-amd64-v0.76.0.tar.zst --confirm
Use an external registry:
zarf init zarf-init-amd64-v0.76.0.tar.zst \
--registry-url=<registry.example.com> \
--registry-push-username=<username> \
--registry-push-password=<password> \
--confirm
External registry parameter descriptions:
| Parameter | Description |
|---|---|
--registry-url | External image registry address |
--registry-push-username | Username used to push images |
--registry-push-password | Password used to push images |
After initialization, subsequent zarf package deploy operations will automatically import images, "rewrite" (actually relying on an admission webhook to redirect image names) the container image field, and deploy Helm charts.
Deploy HAMi AI Platform
All components in the HAMi AI Platform main package are set as optional. Select --components based on your deployment scenario. Please keep the component order as shown in this document.
Component list:
| Component Name | Description | Required | Recommended |
|---|---|---|---|
tools | Ops toolset: jq, nerdctl, etc. | No | As needed |
hami-deploy-scripts | HAMi deployment and preflight scripts | Yes | Yes |
hami | hami-enterprise Helm Chart | No | Yes |
prometheus-crds | Prometheus monitoring CRDs | No | Yes |
prometheus | Kube-prometheus-stack Helm Chart | No | As needed |
gpu-operator | NVIDIA GPU Operator | No | As needed |
gateway-api-crds | Gateway API Standard channel CRD pre-installation | No | As needed |
envoy-gateway | Envoy Gateway (API gateway) | No | As needed |
kantaloupe | HAMi AI Platform (Kantaloupe) | No | Yes |
gateway-api-crds installs the official Gateway API Standard channel v1.5.0 CRD set. If the target cluster already has Gateway API installed, this component will automatically skip and not upgrade.
Platform edition deployment requires a custom Helm Chart values file to override cluster, image, scheduling, and monitoring configurations. During deployment, both --values and --features="values=true" must be passed. The Helm Chart values merge order is: Chart defaults -> in-package values/*.yaml -> --values -> --set-values. The prometheus and gpu-operator packages already include in-package values configurations, so no additional configuration is needed (unless you have special requirements). kantaloupe, however, requires more custom configuration, which is described in detail below.
Prepare custom values
hami-enterprise values
The in-package hami/README.md provides complete values documentation for hami-enterprise. Common configuration items at a glance:
| Parameter | Description | Default |
|---|---|---|
dra.enabled | Whether to enable and deploy DRA | false |
scheduler.leaderElect | Whether to enable leader election for hami-scheduler across multiple nodes. Strongly recommended to disable for single-node clusters. | true |
scheduler.replicas | Adjust the number of hami-scheduler instances | 1 |
scheduler.kubeScheduler.image.registry | Image registry for the kube-scheduler image used by hami-scheduler | registry.cn-hangzhou.aliyuncs.com |
scheduler.kubeScheduler.image.repository | Image repository name for the kube-scheduler image used by hami-scheduler | google_containers/kube-scheduler |
scheduler.kubeScheduler.image.tag | Version of the kube-scheduler image used by hami-scheduler; should match the target cluster | "" |
Minimal configuration example: my-overrides.yaml
dra:
enabled: false
scheduler:
leaderElect: true
The HAMi scheduler depends on a kube-scheduler image that matches the target Kubernetes cluster version. Additional configuration is only required when the target cluster's kube-scheduler is not running inside the cluster (and its image cannot be reused directly from kube-system); this is common in cloud-managed Kubernetes control plane clusters. If a kube-scheduler Pod exists in the cluster, you can skip the following configuration:
scheduler:
kubeScheduler:
image:
registry: your-registry.example.com
repository: google_containers/kube-scheduler
tag: v1.29.8
The built-in kube-scheduler image version in this air-gap package is v1.36.0. If the target cluster's Kubernetes version differs and you cannot reuse the existing in-cluster kube-scheduler, you must prepare and import a matching kube-scheduler image in the offline environment yourself.
kantaloupe values
The in-package kantaloupe/README.md provides the full values documentation for kantaloupe.
kantaloupe requires configuration for feature toggles, service exposure, monitoring metrics collection, and more, so there are many configuration options. Configure as needed. For the complete values reference, see kantaloupe Helm Chart Value Reference.
Common configuration values examples are below. You can combine multiple snippets to form a complete values file:
- Configure default platform administrator credentials
auth:
jwtSecret: "your-own-jwt-secret"
bootstrapAdminUsername: "bootstrap-platform-admin"
bootstrapAdminPassword: "admin12345"
bootstrapAdminFullName: "Platform Administrator"
bootstrapAdminEmail: "admin@email.com"
- Expose services using envoy-gateway NodePort, and use an external LoadBalancer (cloud provider load balancer, self-built load balancer, etc.) to forward L4 traffic.
gateway:
enabled: true
hostnames:
- your-domain.example.com
apiserverCors:
enabled: true
allowCredentials: true
allowOrigins:
- https://your-domain.example.com
envoy:
service:
ports:
http:
nodePort: 30080
https:
nodePort: 30443
type: NodePort
listeners:
- name: http
port: 80
protocol: HTTP
- name: https
port: 443
protocol: HTTPS
tls:
certificateRef:
name: your-domain-tls-secret
redirectFromHttp: true
- Expose services using envoy-gateway NodePort, simple PoC
gateway:
enabled: true
listeners:
- name: http
port: 80
protocol: HTTP
envoy:
service:
type: NodePort
ports:
http:
nodePort: 30080
- Use a LoadBalancer service managed by a cloud provider or bare-metal load balancer controller
gateway:
enabled: true
hostnames:
- your.domain
listeners:
- name: http
port: 80
protocol: HTTP
- name: https
port: 443
protocol: HTTPS
tls:
certificateRef:
name: your-tls-secret
redirectFromHttp: true
envoy:
service:
type: LoadBalancer
ports:
http: {}
https: {}
- Do not use Gateway API; handle service exposure manually.
gateway:
enabled: false
- Replace the Prometheus Query API address (default is
http://prometheus-kube-prometheus-prometheus.monitoring.svc.cluster.local:9090)
apiserver:
prometheusAddr: http://your-prometheus-query-api.com:9090
controllerManager:
prometheusAddr: http://your-prometheus-query-api.com:9090
For production or delivery environments, it is recommended to consolidate into a single my-overrides.yaml containing both HAMi and platform Gateway configurations:
dra:
enabled: false
scheduler:
leaderElect: true
gateway:
enabled: true
service:
type: NodePort
nodePort: 30080
tls:
enabled: false
hamiNamespace: hami-system
Before deployment, it is recommended to verify the values merge result offline:
zarf package inspect values-files hami-ai-platform-v0.0.2-airgap-amd64.tar.zst \
--components=tools,hami-deploy-scripts,hami,prometheus-crds,prometheus,gpu-operator,gateway-api-crds,envoy-gateway,hami-ai-platform \
--values=my-overrides.yaml \
--features="values=true"
Execute Deployment
Full installation, including tools, HAMi, Prometheus, GPU Operator, Gateway API CRD, Envoy Gateway, and AI Platform:
zarf package deploy hami-ai-platform-v0.0.1-airgap-amd64.tar.zst \
--components=tools,hami-deploy-scripts,hami,prometheus-crds,prometheus,gpu-operator,envoy-gateway,hami-ai-platform \
--values=my-overrides.yaml \
--features="values=true" \
--confirm
If the cluster already has HAMi Enterprise deployed, you only need to add Gateway and AI Platform afterward:
zarf package deploy hami-ai-platform-v0.0.2-airgap-amd64.tar.zst \
--components=gateway-api-crds,envoy-gateway,hami-ai-platform \
--values=my-overrides.yaml \
--features="values=true" \
--confirm
If a component remains stuck for a long time, the installation has encountered an issue. You can use zarf tools helm to diagnose the component; if the failure is caused by incorrect values during Helm rendering or installation, fix my-overrides.yaml and rerun the same zarf package deploy ... command.
After an interrupted deployment, resolve the issue and resume with the same zarf package deploy ... --components=... --values=... command. Zarf will skip re-importing images when the digest has not changed; it will perform a Helm upgrade when Helm charts or values have changed.
If zarf package deploy fails due to different Helm resource ownership leading to Kubernetes resource fields conflict, try adding the --force-conflicts flag to force an overwrite.
Enable GPU Nodes
HAMi device-plugin only starts on nodes with the gpu=on label (can be applied manually):
kubectl label nodes <node-name> gpu=on
Verify: kubectl -n hami-system get pods should show hami-device-plugin-* and hami-scheduler-* in Running state.
Monitoring Integration
Ensure the monitoring metric system in the cluster (kube-prometheus-stack Prometheus, VictoriaMetrics vmagent, etc.) can collect HAMi and DCGM-Exporter metrics.
If using Prometheus, the metadata.labels of the ServiceMonitor resource must match the spec.serviceMonitorSelector field of the Prometheus resource; otherwise Prometheus will not collect these metrics.
If using VictoriaMetrics, the metadata.labels of the ServiceMonitor resource must match the spec.serviceScrapeSelector field of the VMServiceScrape resource; otherwise vmagent will not collect these metrics.
Verify Metric Collection
| Exporter | Query Metric | Expected |
|---|---|---|
dcgm-exporter | DCGM_FI_DEV_GPU_UTIL | Returns a non-empty value |
hami-exporter | HostCoreUtilization | Returns a non-empty value |
hami-device-plugin-exporter | GPUDeviceCoreAllocated | Returns a non-empty value |
In addition to exporter metrics, you also need to query kantaloupe_gpu_temp to verify that kantaloupe service metrics are correctly collected.
Licence Acquisition
Please complete the installation tasks above and ensure that all component Pods are running normally before starting the activation process.
Execute the following script to collect licence information (requires kubectl, jq):
# Online script acquisition
curl -fsSL https://public.hami.run/collect-hami-license-info.sh | bash
# Offline installation (included in the package)
bash collect-hami-license-info.sh
After execution, you will see the following JSON content:
{
"esn": "96565d61-986a-4918-aafb-448ff6e3746b",
"deviceInstances": [
{
"uuid": "GPU-ceee905d-48ac-93de-a81b-17c00e1e5e02",
"deviceType": "NVIDIA A10"
}
]
}
Send the above JSON to Dynamia.ai's pre-sales / technical support to obtain the licence.
Post-Activation Verification
# 1. Pod status
kubectl -n hami-system get pods
# 2. GPU resources registered by the Device Plugin
kubectl describe node <gpu-node> | grep -A 5 'Capacity:'
# Expected to see: nvidia.com/gpu: <N> and nvidia.com/gpumem: <MB>
# 3. Submit a test Pod to verify scheduling
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: Pod
metadata:
name: hami-smoke
spec:
restartPolicy: Never
containers:
- name: cuda
image: nvidia/cuda:12.4.0-base-ubuntu22.04
command: ["nvidia-smi"]
resources:
limits:
nvidia.com/gpu: 1
nvidia.com/gpumem: 2000
EOF
kubectl logs hami-smoke
Expected: the nvidia-smi output should show GPU information, and the video memory should be limited to 2000 MiB.
HAMi AI Platform Verification
# 1. Pod Status
kubectl -n kantaloupe-system get pods
# 2. Service Accessibility
kubectl -n kantaloupe-system get svc
After the HAMi AI Platform service is exposed, open the site and confirm that the frontend and backend are working normally.
Create Workload
On the console Workload page, create an application (e.g., gpu-burn):
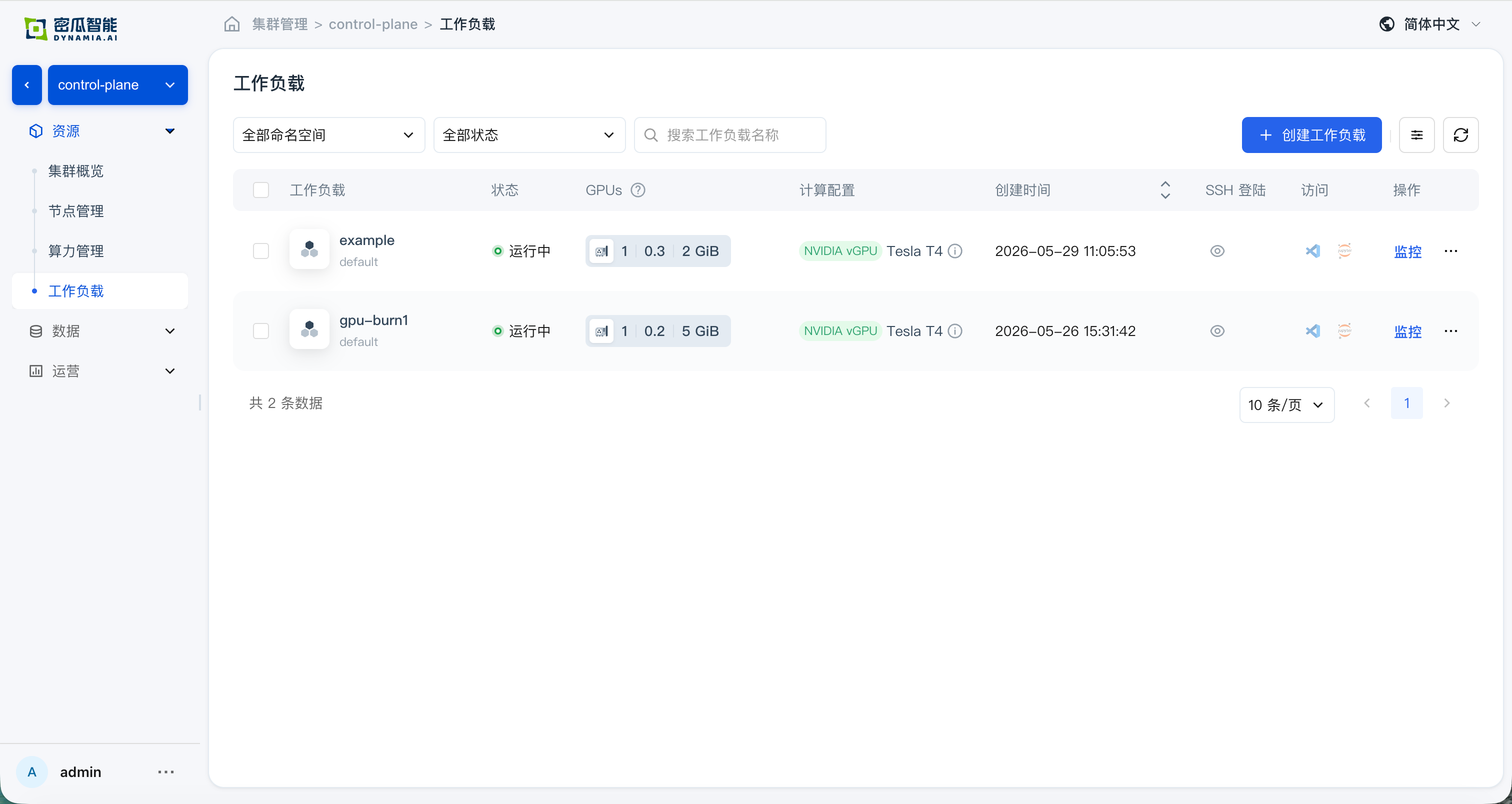
After creation, confirm that the following verification items all pass:
- Creation successful, no errors in the console
- Workload list: application status, search, list metrics, and monitoring panels (GPU SM / GPU MEM / CPU / Memory) are normal; time switching and charts meet expectations
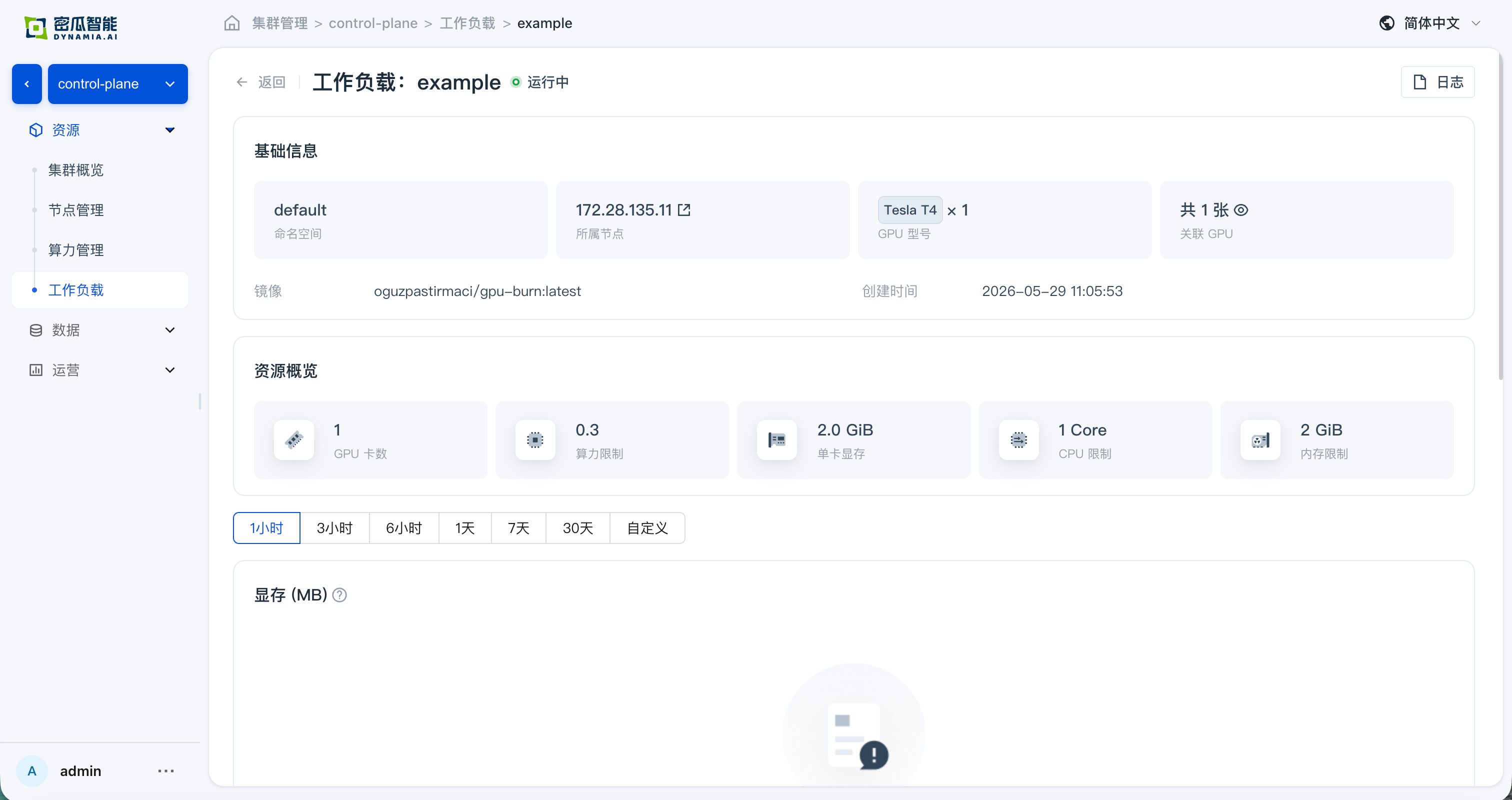
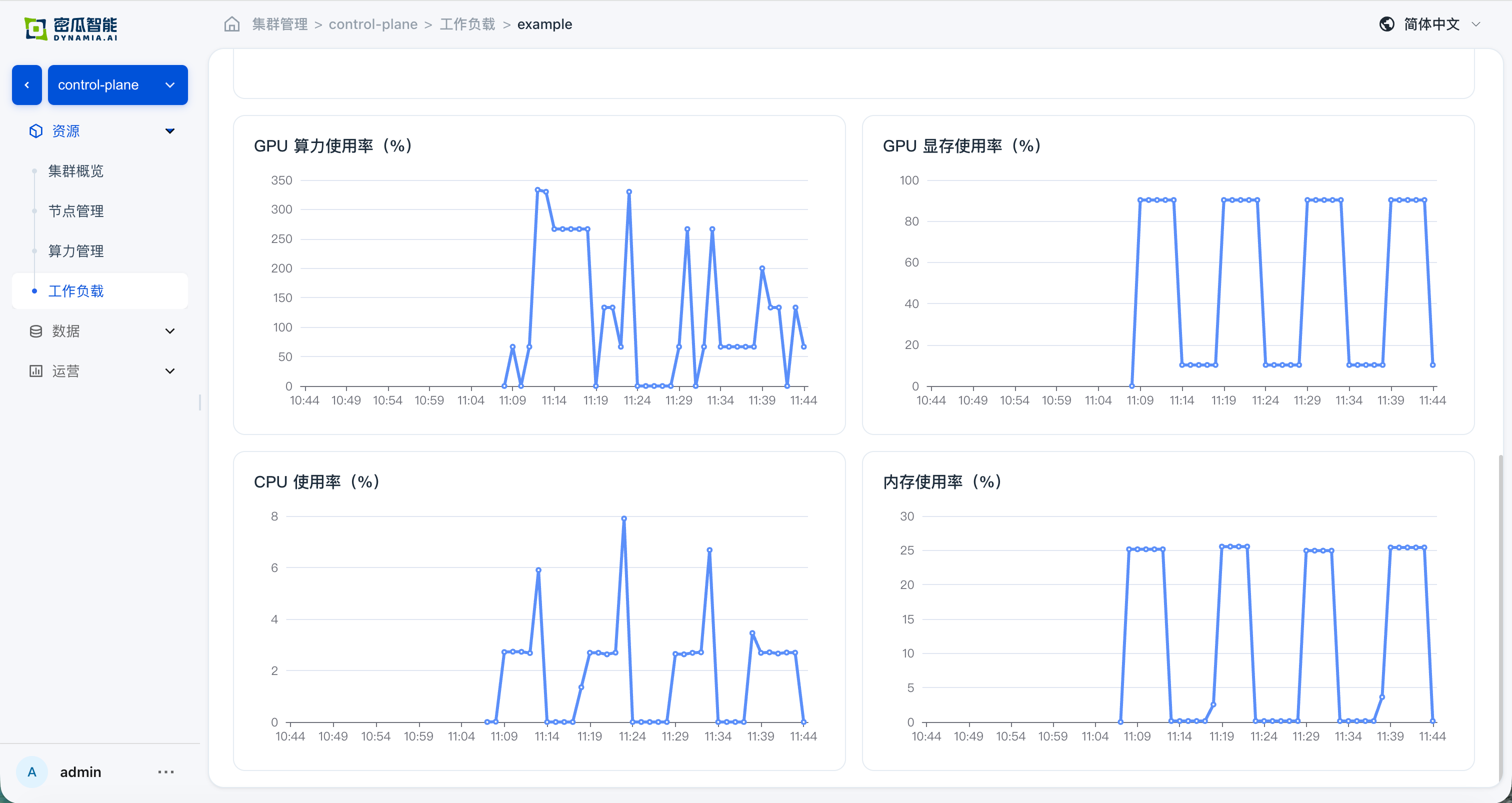
- Application details: basic information, resource overview, and monitoring data are normal; navigating from the detail page to the GPU / Node page, resource overview and monitoring data are normal
Sample Workload Verification
The outer air-gap package already contains two independent Zarf sample packages, so there is no need to manually kubectl apply local YAML.
GPU Burn Verification
zarf package deploy zarf-package-hami-example-gpu-burn-amd64-v0.0.1.tar.zst --confirm
After deployment, check the Deployment / Pod status:
kubectl -n default get deploy turbo-gpu-burn
kubectl -n default get pods -l app=turbo-gpu-burn
kubectl -n default logs -l app=turbo-gpu-burn --tail=50
This sample creates default/turbo-gpu-burnDeployment; clean it up as needed after verification:
kubectl -n default delete deploy turbo-gpu-burn
vLLM + Qwen Verification
zarf package deploy zarf-package-hami-example-vllm-qwen-amd64-v0.0.2.tar.zst --confirm
After deployment, check the inference service status:
kubectl -n default get deploy vllm-qwen3
kubectl -n default get pods -l app=vllm-qwen3
kubectl -n default get svc vllm-qwen3-webui
Once the Pod is ready, access Open WebUI via any node IP + NodePort (30081):
# Get cluster node IP (any reachable node is fine)
kubectl get nodes -o wide
# Access via browser
# http://<node-ip>:30081
Open WebUI is automatically connected to the vLLM sidecar in the same Pod; open the page to start interacting.
If the Pod remains Pending, first check whether the license is activated, whether GPU nodes are labeled with gpu=on, and whether the node GPU drivers are normal.
Troubleshooting
Common inspection commands:
kubectl get pods -A | grep -E 'hami|gpu-operator|prometheus|vllm|gpu-burn'
kubectl get events -A --sort-by=.lastTimestamp | tail -50
zarf package list
Collect diagnostic information:
bash collect-cluster-info.sh
Manually inspect the main package contents:
# Extract the main package to a temporary directory; ensure sufficient space
zarf tools archiver decompress hami-enterprise-v0.0.2-airgap-amd64.tar.zst /tmp/hami-enterprise-pkg
# View package definition
cat /tmp/hami-enterprise-pkg/zarf.yaml
# View rendered manifests offline
zarf package inspect manifests hami-enterprise-v0.0.2-airgap-amd64.tar.zst --components=hami
# View rendered values offline
zarf package inspect values-files hami-enterprise-v0.0.2-airgap-amd64.tar.zst \
--components=hami \
--values=my-overrides.yaml \
--features="values=true"
Manually inspect the main package contents:
# Extract main package to temporary directory; reserve enough space
zarf tools archiver decompress hami-ai-platform-v0.0.2-airgap-amd64.tar.zst /tmp/hami-ai-platform-pkg
# View package definition
cat /tmp/hami-ai-platform-pkg/zarf.yaml
# View rendered manifests offline
zarf package inspect manifests hami-ai-platform-v0.0.2-airgap-amd64.tar.zst \
--components=hami-ai-platform \
--values=my-overrides.yaml \
--features="values=true"
# View rendered values offline
zarf package inspect values-files hami-ai-platform-v0.0.2-airgap-amd64.tar.zst \
--components=hami,hami-ai-platform \
--values=my-overrides.yaml \
--features="values=true"
FAQ
| Symptom | Possible Cause | Resolution |
|---|---|---|
| Image pull fails | The node has no external network or poor connectivity to ghcr.io. | Contact Dynamia.ai pre-sales/technical support to obtain a domestic mirror registry address or an All-in-One offline bundle. |
hami-device-plugin Pod Pending or missing | The node is not labeled with gpu=on. | kubectl label nodes <node> gpu=on |
hami-device-plugin Pod CrashLoopBackOff | Conflicts with the NVIDIA default device-plugin. | Disable the GPU Operator devicePlugin (--set devicePlugin.enabled=false). |
| HAMi metrics not found | The Prometheus resource's serviceMonitorSelector does not match the labels in the ServiceMonitor resource. | Align prometheus/prometheus-kube-prometheus-prometheus's spec.serviceMonitorSelector and hami-enterprise's serviceMonitor labels. |
nvidia-smi error | GPU driver not ready. | Check the driver Pod status in the gpu-operator namespace. |
Sample workload Pending | License not activated, insufficient GPU, or missing node labels. | Check the license, GPU node labels, and kubectl describe pod events. |
Gateway has no ingress address | Envoy Gateway not ready or Service type not suitable for the cluster. | Check the envoy-gateway-systemService and Gateway status. |
Limitations of Installing Components with Zarf
Cannot mix internal and external image registries in the same namespace (using multiple registries in the same cluster has limitations)
Zarf uses an admission webhook to silently replace the images of all containers in a managed namespace with versions from the private registry. In a cluster, some namespaces can bypass Zarf and access other registries normally, but you cannot use images from different registries within the same namespace.You can ignore this behavior by labeling the namespace with zarf.dev/agent=ignore, allowing you to use other registries in that namespace instead of the registry specified by zarf init --registry-url ....
Native Helm cannot be used to manage the same set of resources
Once Zarf has taken over a set of components, attempting to manage the same resources with another Helm workflow can easily lead to ownership conflicts, upgrade collisions, or ambiguous state. This is not a Zarf-specific issue; it is an almost inevitable result when delivery boundaries are not clearly defined. Zarf makes it convenient to spin up a set of components, but you cannot install them and then kick Zarf aside and return to Helm for daily iteration.Therefore, unless necessary, please rely on the Migua AI team for regular version upgrades and do not iterate HAMi Enterprise on your own.
Difficult to iterate flexibly
Zarf's design means that every transfer carries the full software stack. This inherently precludes "flexibility."
Get Support
- Email: info@dynamia.ai
- Pre-sales / Technical Support: 400-026-7800
- Customers with signed commercial contracts please submit issues through the dedicated support channel